
{kind=link}
Assist CleanTechnica’s work by way of a Substack subscription or on Stripe.
Leapmotor T03 wins the Metropolis Automobile class for the primary time ever!
EVs are selecting up in Europe, with some 246,000 plugin autos being registered in Europe in August. That’s up 36% 12 months over 12 months (YoY), above the yearly progress charge of 27%.
It is a constructive signal when contemplating that the general market (at present at ~8.7 million models YTD) is principally stagnant (up 5% in August, 0% YTD).
Apparently, whereas BEVs appear to be on a gradual progress charge (in August, they had been up 27% YoY, to 163,000 models), PHEVs are actually selecting up the tempo, leaping 56% YoY in August, their highest progress charge in over three years. They had been spearheaded by the #4 BYD Seal U PHEV (aka Euro-spec BYD Tune PHEV), however the VW Tiguan PHEV can be experiencing a second youth, due to the brand new technology of the mannequin. PHEVs scored over 83,000 gross sales in August, and their YTD numbers are actually up 36% to shut to 793,000 models.
As such, August noticed the BEV share of the general European auto market attain 21% (31% for plugin autos general if we add PHEVs to BEVs), which was their second highest rating ever, after the 22% of August 2023.
In comparison with August 2024, BEVs jumped 4 share factors — 12 months in the past, the BEV share was 17% — which represented a 24% progress charge. If this progress charge (24%) continues within the coming years, we must always have 62% BEV share by 2030 and may attain 100% BEV share by 2033.
What do you concentrate on this goal? Am I being too optimistic?
A observe about plugless hybrids (HEVs): in August, they grew 12% YoY, to 33% share. Added to the 31% of plugins, that implies that 64% of all new automobiles in Europe had some type of electrification. It additionally meant that the August end result was under the YTD end result (35%)…. Is peak HEV coming quickly? Fingers crossed.
Regardless of this constructive month, BEVs saved their year-to-date numbers at 18% (27% for PHEVs and BEVs mixed).
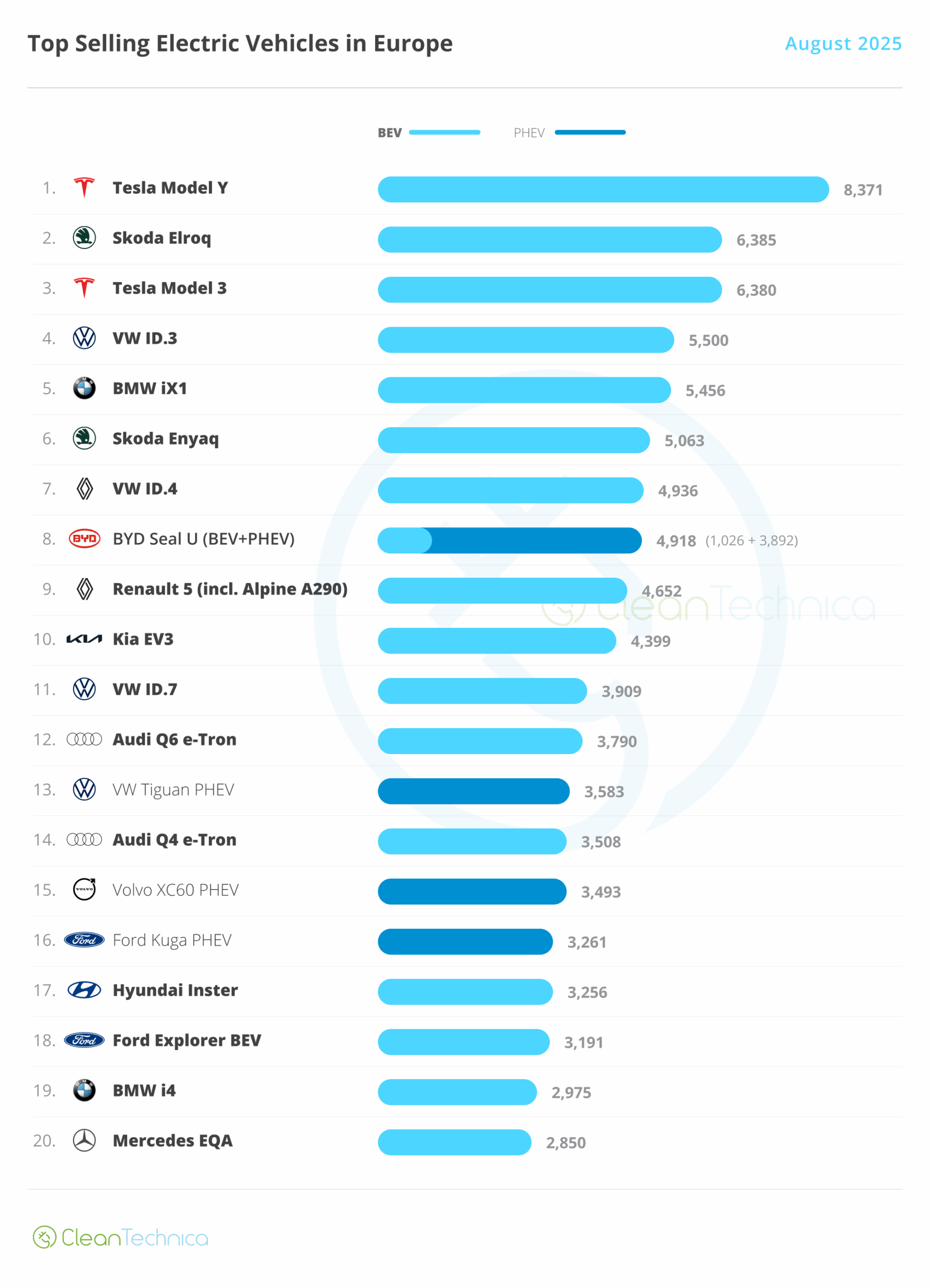
The massive information this month was the Tesla Mannequin Y, which returned to the month-to-month management place. Right here’s a extra detailed evaluation of the highest 5 EVs this month:
#1 Tesla Mannequin Y — Tesla’s star participant delivered 8,371 gross sales, with the crossover thus returning to the highest of one of the best sellers record in Europe. Apparently, whereas the older Mannequin 3 grew 15% in August, the more energizing Mannequin Y was really down in August, by 38% YoY. Causes for this? Properly, the Mannequin Y redesign was much less lucky than that of the Mannequin 3. In any case, the design workforce took inspiration for the brand new Mannequin Y on the failure-tastic Cybertruck. Compared, the Toyota-tized Mannequin 3 seems to be way more pleasant, even when much less cool, than the unique Porsche-inspired Mannequin 3/Y. However … Tesla is discounting the Mannequin Y greater than the Mannequin 3, so the crossover’s slowdown can’t be defined by Tesla’s pricing coverage. Is it simply an unlucky design? Elevated competitors? What do you assume?
#2 Skoda Elroq — After an in depth race with the Tesla Mannequin 3, the lately launched Elroq gained one other medal in August, due to 6,385 registrations. Will we see it go north of the ten,000-unit mark in September? Volkswagen Group has struck gold with this one. Regardless of minimal effort (principally, it shortened the Enyaq), Skoda gained an everyday prime three presence. Though not as spacious as its larger sibling, it compensates for that with a aggressive value, beginning at 34,000 euros, which makes it one of many most cost-effective compact crossovers available on the market, Chinese language included. May this be the brand new value-for-money king?
#3 Tesla Mannequin 3 — The Tesla sedan’s third place end got here due to 6,380 registrations in August, a big 15% gross sales improve YoY. Though, if we examine to August 2023, gross sales had been down 46%…. This allowed the US automaker to win each gold and bronze in August. The competitors is growing by the day, and it’ll turn into tougher for the Texan model to realize two presences within the podium. At 49,000 models delivered this 12 months, the Mannequin 3 is again at 2022 gross sales ranges, a time when BEVs had been promoting half of what they’re promoting as we speak….
#4 VW ID.3 — The German hatchback is lastly dwelling as much as its promise, profitable one other podium place in August due to 5,500 registrations. Benefitting from a refresh, and a big value reduce to assist issues alongside, the VW mannequin noticed its gross sales bounce over 55% in August, permitting it to turn into one of the best promoting electrical hatchback in August. Anticipate the Volkswagen hatchback to proceed operating at a tempo of some 6,500 models per 30 days, and profitable a number of prime 5 presences in consequence.
#5 BMW iX1 — BMW’s compact crossover is having a second and managed to win one other prime 5 presence, due to 5,456 registrations in August. This crossover has turn into a spine of BMW Group’s success, serving to the corporate to remain afloat till the arrival of the cavalry (ahem, the upcoming Neue Klasse BEVs…). Regardless of minimal effort — principally, it’s the BEV model of the ICE BMW X1 — gross sales are up 46% YoY. Common specs (65 kWh battery, 130 kW DC charging) and the badge (and lease charges) nonetheless matter in lots of European markets, which helps it to remain profitable.

Exterior the highest 5, the highlights come from Hyundai, with the Korean make inserting the lately launched Inster funky hatchback onto the desk, at #17, with 3,256 models.
One other mannequin shining was the #18 Ford Explorer EV. With 3,191 gross sales, Ford’s crossover with a VW coronary heart is discovering its spot available on the market, which raises the query — Will we see a future Ford Fiesta EV based mostly on the upcoming VW ID.2? Fingers crossed….
Exterior the highest 20, the spotlight is the Leapmotor T03, with the small Chinese language EV profitable for the primary time the Metropolis Automobile class, due to 1,439 models, which was sufficient to beat the long-running chief Fiat 500e (1,248 models) and even the a lot hyped BYD Dolphin Surf (Euro-spec BYD Seagull), that collected 1,315 models.
Nonetheless, it’s unhappy that the chief of the A-segment has collected simply 1,439 models in August, when the complete dimension chief, the Audi A6 e-tron, registered 2,253 in the identical interval. this subject with a extra constructive view, which means that the future Renault Twingo EV, set to land in 2026, may have loads of alternatives to develop.

Trying on the 2025 rating, as anticipated, August was a quiet month. The Skoda Elroq and Tesla Mannequin 3 each rose two positions, to fifth and sixth, respectively.
It is going to be fascinating to see how these two will behave in September, as each are anticipated to have posted five-digit scores that month. That gross sales stage will permit them to climb a couple of extra positions, so the Renault 5’s podium place will in all probability go to one in every of these two. Query is, which one?
One other mannequin that may doubtless go up subsequent month, would be the BMW iX1, thus becoming a member of the highest half of the desk.

Within the second half of the desk, the one place change was the Cupra Born climbing one place, to #19, on the expense of the Toyota C-HR PHEV, now right down to #20.
Volkswagen Group has 9 representatives within the desk, which is beginning to appear to be what BYD is doing in China….
Having a fast take a look at the August general model rating, the highlights had been the numerous drops of #17 Tesla (-23% YoY), which nonetheless was a greater end result than the YTD end result (-32%), which might imply that the Texan’s fall into the abyss is bottoming out in Europe, whereas #19 Volvo (-30% YoY) is affected by the EX30’s downturn, the compact crossover was down 68% YoY in August, to little greater than 2,000 models.
#20 SEAT was down 16% YoY in August, however that isn’t actually that regarding for the Volkswagen Group, once we take into account that its different Spanish model, the extra aspirational Cupra, was #15 and posted a 56% progress charge, the most important of the highest 20.
Simply outdoors the highest 20 (however not for lengthy…), we have now China’s BYD, in #22, posting a tremendous 217% progress charge YoY. That’s all due to its sprawling lineup, now as much as 10 totally different fashions, with 8 BEVs and a pair of PHEVs. (At this tempo, BYD will surpass Mercedes on the variety of totally different fashions supplied by … subsequent 12 months)

As for the plugin auto model rating, the chief, Volkswagen, has misplaced share (11.2% in August vs. 11.3% in July). Nonetheless, it holds a cushty 2.2% share lead over #2 BMW.
Which means the German make is on its solution to ending a three-year Tesla reign in Europe (2022, 2023, 2024), profitable its first producer title since 2021.
Talking of Tesla, the Texan automaker noticed its share rise by 0.1% from 5.6% to five.7%, conserving its #4 spot. Not unhealthy, however … we’re speaking in regards to the trophy holder. Tesla’s 2024 title was its third in a row, and now it’s seeking to safe a spot within the prime 5! The top of an period?
Under the highest 5, a deserving point out goes to rising BYD, which noticed its share develop to 4.3%, a 0.1 share level improve over July.
The Chinese language model surpassed Kia in August, and is now eighth. However Skoda and Audi (5.3% every) are too far forward to get caught this 12 months. Subsequent 12 months, nevertheless…. Heck, we’d even see BYD run for the rostrum in 2026!

Arranging issues by automotive group, Volkswagen Group is firmly within the lead, regardless of dropping 0.2% share in August. It’s now at 27.8% share, a market share that’s similar to BYD’s in China and Tesla’s within the USA. This is a crucial metric for the German conglomerate if it needs to remain related in a completely electrified international automotive market.
In case you can’t win at residence….
BMW Group (10.6%) remained comfy within the runner-up place in August, whereas #3 Stellantis’ freeway to hell appears to haven’t any finish (8.9% in July vs. 8.7% now). With too many manufacturers and too little cash to develop them, perhaps it could be good to promote a few them? Say, Lancia, Chrysler, and Maserati? These storied makes want consideration and many cash to ensure that them to develop and flourish, and proper now, these two gadgets are in brief provide at Stellantis….
Oh, and if DS and Abarth rejoined Citroen and Fiat, that wouldn’t damage both.
However again to the highest 5: Hyundai–Kia (8.1%) profited from a very good month from Hyundai, which compensated for a slower month from Kia, and remained in 4th, whereas #5 Geely (7.7%) remained secure, regardless of Volvo’s woes.
Whereas Volvo is the primary perpetrator for slowing gross sales, Polestar, Zeekr, and Lynk & Co helped to compensate the Swede’s fall. That Volvo EX60 can’t come quickly sufficient…
Join CleanTechnica’s Weekly Substack for Zach and Scott’s in-depth analyses and excessive stage summaries, join our every day e-newsletter, and comply with us on Google Information!
Have a tip for CleanTechnica? Need to promote? Need to recommend a visitor for our CleanTech Discuss podcast? Contact us right here.
Join our every day e-newsletter for 15 new cleantech tales a day. Or join our weekly one on prime tales of the week if every day is just too frequent.
CleanTechnica makes use of affiliate hyperlinks. See our coverage right here.
CleanTechnica’s Remark Coverage